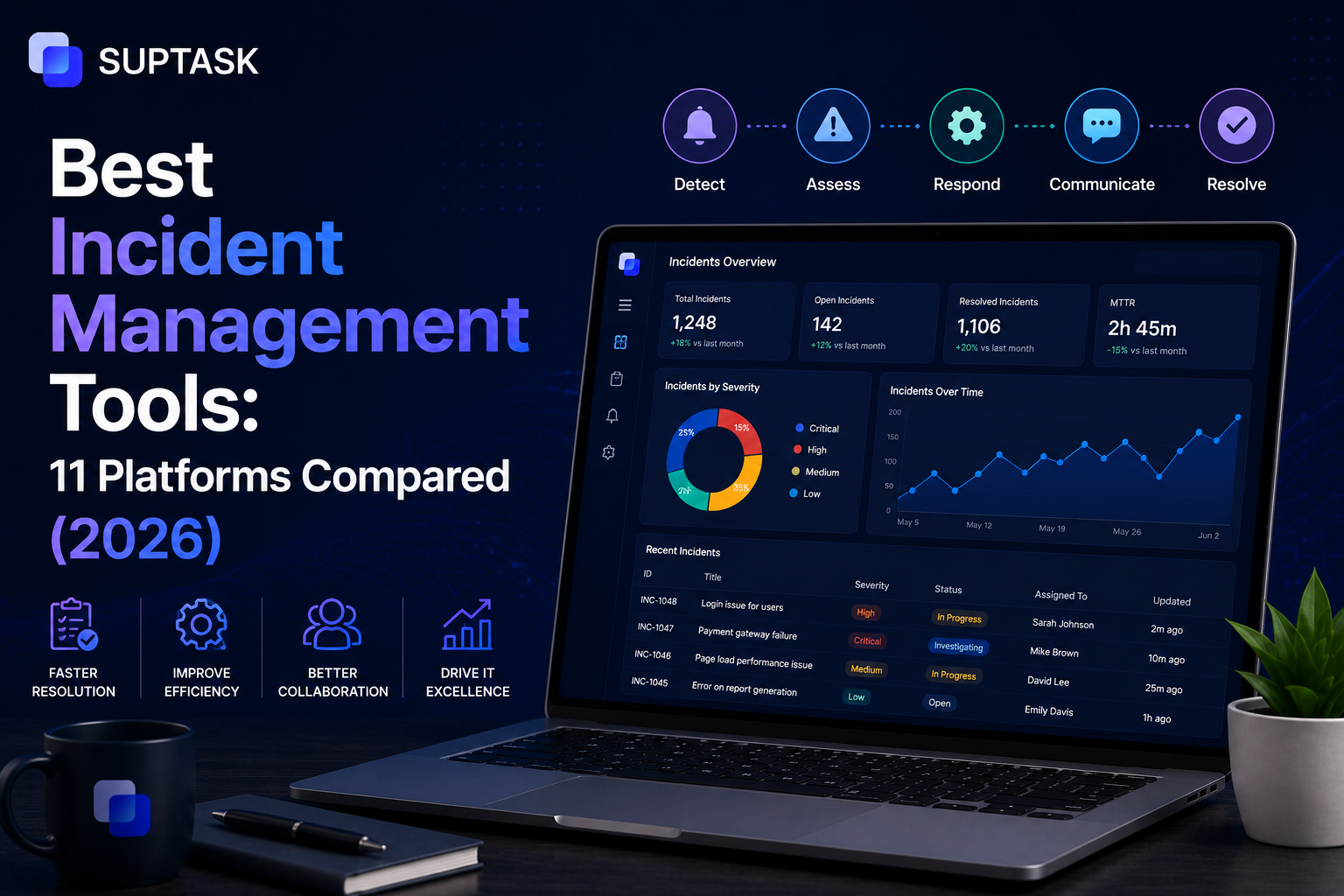
Not all incident management tools do the same job. Some are made for on-call alerting, some for running a live incident, some for correlating alerts with AI, some live inside Slack, and some are just a part of a bigger ITSM platform.
So, each incident management tool does different things. So, how can you choose the right one for your needs? That’s why we have covered the 11 best incident management tools in this blog, so you can learn about them and choose the one that aligns with your requirements.
So, let’s get started.
How do we evaluate these tools?
As said earlier, we will help you with recommendations for the best incident management tools, but how did we select those tools? We have compiled a list of the best ones available and weighed each of them based on their specification.
- On-call and alerting maturity: We have reviewed their features, such as on-call schedules, escalations, and keeping everyone informed and involved in the thread.
- Incident coordination: How proficient is the tool in resolving a live incident, role assignment, and efficient communication?
- Integration opportunities: We have explored their capabilities to integrate with different systems, so you can ensure that it can work with your existing tools too.
- AI and automation depth: AI capabilities include auto-correlating alerts, root cause identification, and incident summarisation.
- Post-incident workflow: The tool must be able to learn from incidents resolved and create a knowledge base that can be referred to solve occurrences more easily.
- Pricing transparency: Price must be transparent so you can plan the budget accordingly.
- Where teams actually work: Whether it is portal-based, Slack, or Teams-native, or somewhere in between.
We have grouped these tools according to their use cases. So, there is no best tool here, the right one is subject to your team size, the stack you are already working on, and how many incidents you have to deal with.
Best incident management tools: Quick comparison table
Here is the whole list at a glance before we get into each one. The starting prices are published entry points, and they change often, so treat them as a guide and check the vendor before you buy.
The 11 incident management tools (grouped by use case)
On-call alerting and escalation
1. PagerDuty: Best for on-call alerting at scale
PagerDuty is an on-call tool and is still the default for teams that page engineers and need escalations they can trust. It is built around alerting and incident response, and it is used by everyone from startups to very large engineering orgs.
Key features:
- On-call schedules and layered escalation policies.
- Multi-channel alerts over push, SMS, phone, and Slack.
- 700+ integrations with monitoring and ticketing tools.
- An AIOps add-on that groups related alerts.
- A solid mobile app for responders.
Pricing: Free for up to 5 users, Professional from around $21/user/mo, with AIOps and advanced tiers costing more.
Pros: It has the best-in-class capabilities for alerting and escalation, along with an extensive integration ecosystem.
Cons: It gets expensive once you add AIOps, and it is more of an alerting tool than a coordination one.
Best for teams of almost any size that need a reliable on-call, especially once they outgrow the free tier.
2. Splunk On-Call: Best for teams already on Splunk
Splunk On-Call, formerly VictorOps, is alerting wired into Splunk's observability stack. Therefore, it is the right incident management tool for teams that are already using Splunk for monitoring and logs, and want their paging in the same place.
Key features:
- On-call scheduling and alert routing.
- An incident timeline with annotations.
- Tight integration with Splunk data.
- Postmortem timeline capture.
- Mobile alerting.
Pricing: Tiered and sold through Splunk, with no transparent public free tier, though a trial is available.
Pros: It fits Splunk data naturally, and the incident timeline is genuinely useful.
Cons: Most of the value only shows up if you are already in Splunk, and the pricing is not transparent.
Best for engineering and ops teams that have standardised on Splunk and want alerting close to their telemetry.
Engineering incident coordination
3. Incident.io: Best for Slack-first incident coordination
Incident.io is a modern, Slack-native platform built around running a live incident rather than just paging someone. It is popular with product-led engineering teams that already use Slack.
Key features:
- Incident creation and role assignment straight from Slack.
- Automated status updates and stakeholder comms.
- Built-in postmortems.
- An on-call product that has been added more recently.
- Integrations with monitoring and ticketing.
Pricing: Free for up to 5 users, paid from around $21/user/mo.
Pros: The live-incident workflow inside Slack is excellent, and the product is intuitive to use.
Cons: It started as a communication-first tool, so alerting is newer, and the cost may increase with the number of responders.
Best for Slack-based engineering teams that want structured incident response without sending anyone to a portal.
4. FireHydrant: Best for postmortems and learning
FireHydrant is an incident response with unusually strong postmortem and retrospective workflows. It suits teams that genuinely want to learn from incidents, not just close them.
Key features:
- Automated runbook steps during an incident.
- Role assignment and clear incident roles.
- Retrospective and postmortem templates.
- Slack integration.
- A service catalogue to map ownership.
Pricing: Starter from around $20/user/mo, with a Pro plan at roughly $6,000 a year, billed annually only.
Pros: The postmortem workflow is among the best, and the process automation is strong.
Cons: Alerting capabilities are available as an add-on, therefore, the pricing will be increased in addition to the tier you are on.
Best for mid-size engineering teams that take retrospective culture seriously and want tooling that supports it.
5. Rootly: Best for Slack-native coordination with AI
Rootly is a Slack-native incident tool positioned close to Incident.io, with a growing AI SRE angle. If you are choosing between the two, it is worth trialling both.
Key features:
- Slack-driven incident workflows.
- Automated roles and communications.
- Retrospectives and timelines.
- AI assistance for incident steps and summaries.
- Integrations across the stack.
Pricing: incident response from around $20/user/mo, with separate tiers for on-call and the AI SRE features.
Pros: A strong Slack workflow and active development on the AI side.
Cons: The separate tiers add up, and it overlaps heavily with Incident.io, so the choice often comes down to feel.
Best for Slack-first teams that want coordination plus a real AI assist.
AIOps and observability-integrated
6. Better Stack: Best for monitoring and incidents in one
Better Stack bundles uptime monitoring, logs, and incident management into one modern tool. It appeals to smaller teams that would rather not stitch three products together.
Key features:
- Monitoring and status pages.
- On-call and escalations.
- An incident timeline.
- Log management.
- A wide set of integrations.
Pricing: Pricing starts from $29/mo, though per-responder and add-on fees can stack up.
Pros: Monitoring and incidents live together, the UI is modern, and the entry price is reasonable.
Cons: It is less deep than the specialist tools, and the add-ons add cost as you grow.
Best for small-to-mid teams that want their monitoring and incident response in a single place.
7. Datadog Incident Management: Best for teams already on Datadog
Datadog Incident Management is built into the Datadog platform, so it is the obvious choice if your monitoring already lives there.
Key features:
- Incidents raised straight from Datadog monitors.
- A full incident timeline tied to telemetry.
- Slack integration.
- Postmortems.
- Deep links into your Datadog data.
Pricing: Part of the Datadog platform on a responder basis, so it only adds up if you are already paying for Datadog.
Pros: No context-switching from monitoring to incidents, and the telemetry context is rich.
Cons: It is only worth it inside Datadog, and the overall platform cost is high.
Best for teams that have standardised on Datadog for observability.
8. Grafana Incident: Best for Grafana-stack teams
Grafana Incident is available with Grafana Cloud and is one of the best tools for on-call paging. This might be the right choice if you have already been using Grafana and the Prometheus stack.
Key features:
- Incident capabilities offered through Grafana dashboards and alerts.
- Grafana OnCall features for scheduling and paging.
- Slack integration.
- Incident timelines.
- Automatic summaries.
Pricing: Included in Grafana Cloud, with a free tier also available.
Pros: It is the best choice if you have a Grafana stack. Also, it has a free trial available to get started.
Cons: It might not be the right choice to be used as a standalone application.
Best for teams already running Grafana and Prometheus who want incidents close to their dashboards.
Slack-native incident coordination
9. Suptask: Best for Slack-native ticketing with incident workflows
Suptask is a Slack-native tool that allows teams to work inside Slack, and tickets are created there from messages themselves. Therefore, teams that are already using Slack will find it more helpful for them.
Key features:
- Tickets created from Slack messages.
- Agents work in the thread.
- Routing and assignment.
- AI thread summaries.
- SLA tracking and integrations.
Pricing: Suptask pricing starts from $15/agent/month (Starter), Professional at $24, Growth at $38, along with custom pricing available. The Growth plan also comes with a 14-day free trial.
Pros: There is no portal, so people work where they already are, and time-to-value is fast.
Cons: It is not a dedicated alerting or on-call tool, so heavy paging needs pairing with one, and the ecosystem is younger than the incumbents.
Best for Slack-first teams that want lightweight incident coordination and ticketing in the same place.
ITSM platform-integrated
10. ServiceNow Incident Management: Best for enterprise ITSM at scale
ServiceNow Incident Management is incident handling inside the enterprise ITSM standard. It is for large organisations that want incidents tied into full ITIL practices and a CMDB.
Key features:
- ITIL-aligned incident, problem, and change management.
- CMDB integration.
- Now Assist AI for routing and summaries.
- Major incident management.
- A very broad integration catalogue.
Pricing: Contact sales, and it is priced at the enterprise end.
Pros: It is comprehensive, the AI is capable, and it scales to the largest organisations.
Cons: It is expensive, the deployment is long, and it is overkill for most engineering teams.
Best for large enterprises that are already on ServiceNow or moving to it.
11. Jira Service Management: Best for Atlassian-stack teams and Jira users
Jira Service Management is Atlassian's ITSM tool and the natural choice if you are already in the Atlassian stack. It now also absorbs Opsgenie's on-call and Halp's chat intake, so it covers alerting, Slack, and Teams intake, and ITSM in one place.
Key features:
- Incident, request, and change management.
- Built-in on-call, carried over from Opsgenie.
- Slack and Teams intake, carried over from Halp.
- Tight integration with Jira and developer tooling.
- Atlassian Intelligence for AI assistance.
Pricing: Free for up to 3 agents, Standard from around $20/agent/mo.
Pros: It bridges development and operations, combines on-call with ITSM, and is the obvious pick for Jira users.
Cons: the value is really only there inside Atlassian, and it can get complex to configure.
Best for engineering-heavy organisations already running Jira.
How to choose: matching tools to your situation
Now you might have an understanding of the best incident management tools, so the next thing is to decide which tool to choose. As you have seen, each tool has different offerings, so the selection of the right one can be determined based on your needs.
- You have 2 to 5 engineers and a few incidents: You can start with PagerDuty's free tier or Better Stack's starter plan.
- You are already on the Atlassian stack: Jira Service Management is the obvious pick, since it now carries the on-call that used to be Opsgenie.
- You are already on Datadog: Datadog Incident Management is the easy choice, since your monitoring already lives there.
- Your team lives in Slack: You can choose tools like Suptask, Incident.io, or Rootly, all of which run the incident inside Slack instead of a portal.
- You need ITIL-aligned incident management with full ITSM scope: ServiceNow Incident Management or Jira Service Management.
- You need strong postmortem and learning workflows: FireHydrant or Rootly do this best.
- You manage high-frequency, low-severity incidents: You can get started with on-call alerting tools like PagerDuty.
- You handle low-frequency, high-severity incidents: Coordination tools like Incident.io and FireHydrant can do this job.
AI and AIOps in incident management
AIOps are among the core features of almost all incident management tools. However, not all of the tools have the capabilities that deliver what marketing says. So, it is a must to know what AI can do in incident management, helping you to make the right choice:
- Auto-correlation of alerts: AI can group relevant alerts together, so the relevant cases can be seen at once.
- Suggested root cause: AI can analyze past incidents, deployment, and system patterns to identify the root causes for frequent problems.
- Auto-drafted postmortems: AI turns the Slack thread and ticket history into a first draft of the post-incident summary, so keeping track of the ticket.
- Predictive detection: AI flags anomalies before they breach an SLA, so you can identify incidents before your customers do.
- Conversational incident coordination: AI assists the coordination itself, suggesting the next step or the right on-call hand-off in the moment.
Every incident management tool discussed so far has introduced AI in 2026, such as Better Stack, Datadog, Splunk On-Call, and ServiceNow with AI Platform along with newer Slack-native tools like Incident.io and Rootly.
Common pitfalls in incident management tool selection
The selection of the incident management tool may also lead to a few of the most common challenges. Here we have compiled a few of them, so you can plan the selection accordingly to avoid these challenges:
- Buying for alerting when you need coordination: You should be definitive with your requirement. For example, PagerDuty is the right choice for paging, but it might not replace the need for a coordination tool. So, be specific with your requirements.
- Adding a tool without fixing the process: a tool will not sort out unclear on-call rotations, a severity scale nobody agreed on, or a team with no postmortem habit. Fix the process first, or the tool just automates the mess.
- Choosing on feature count: The tool might have a lot of features offered, but you should focus on shortlisting a tool that has the features your team needs.
- Underestimating Slack or Teams as the real war room: When an incident is logged, your team must be informed and should start working on the chat where the incident was logged.
- Ignoring postmortems: Most teams often emphasize detection, alerting and ignore the learning part. However, the best value of the tool can be achieved when it learns continuously and ensures similar incidents do not keep occurring.
- Going enterprise too early: ServiceNow is excellent at scale, but for an engineering team under 200 people, it is usually overkill, and the deployment alone will outweigh the benefit.
Frequently asked questions
1. What's the difference between incident management and incident response?
They overlap, and people use the terms loosely, but there is a difference. Incident response is the act of dealing with an incident while it is happening, detecting it, responding, and resolving it. Incident management is the wider discipline around that: the process, the roles, the tooling, and the learning afterwards. In short, incident response is what you do during the incident, and incident management is the whole process around it, before, during, and after.
2. Do small engineering teams need a dedicated incident management tool?
Not always. A team of a handful of engineers with infrequent incidents can often get by with a Slack channel and the free tier of an on-call tool like PagerDuty. A dedicated tool starts to earn its place once incidents become frequent enough, or complex enough, that coordinating them by hand is costing you real time. Until then, simpler is fine.
3. What's the cheapest reliable incident management tool?
For pure on-call, PagerDuty and Incident.io both have free tiers for up to five users, which is enough for a small team. If you have outgrown free but want to stay cheap, Zenduty starts around $5 a user a month, and Better Stack bundles monitoring and incidents from about $29 a month. Cheap and reliable are not at odds here, the entry tiers of the main tools are genuinely usable.
4. How long does it take to roll out incident management tooling?
It depends on the tool. A Slack-native or on-call tool can be running in a day or two, since there is little to configure beyond schedules and integrations. A full ITSM-integrated setup like ServiceNow takes far longer, often weeks or months, because you are wiring it into the rest of your IT estate. The bigger the platform, the longer the rollout.
5. Can AI fully automate incident response?
Not yet, and probably not soon. AI is good at the supporting work, correlating alerts, suggesting a root cause, drafting the postmortem, and flagging anomalies early. But the judgment calls during a serious incident, deciding what to prioritise, what to communicate, and when to escalate, still need a human. The realistic picture is AI doing the heavy lifting around the edges while people stay in command.